
计算机系统基础
第一章
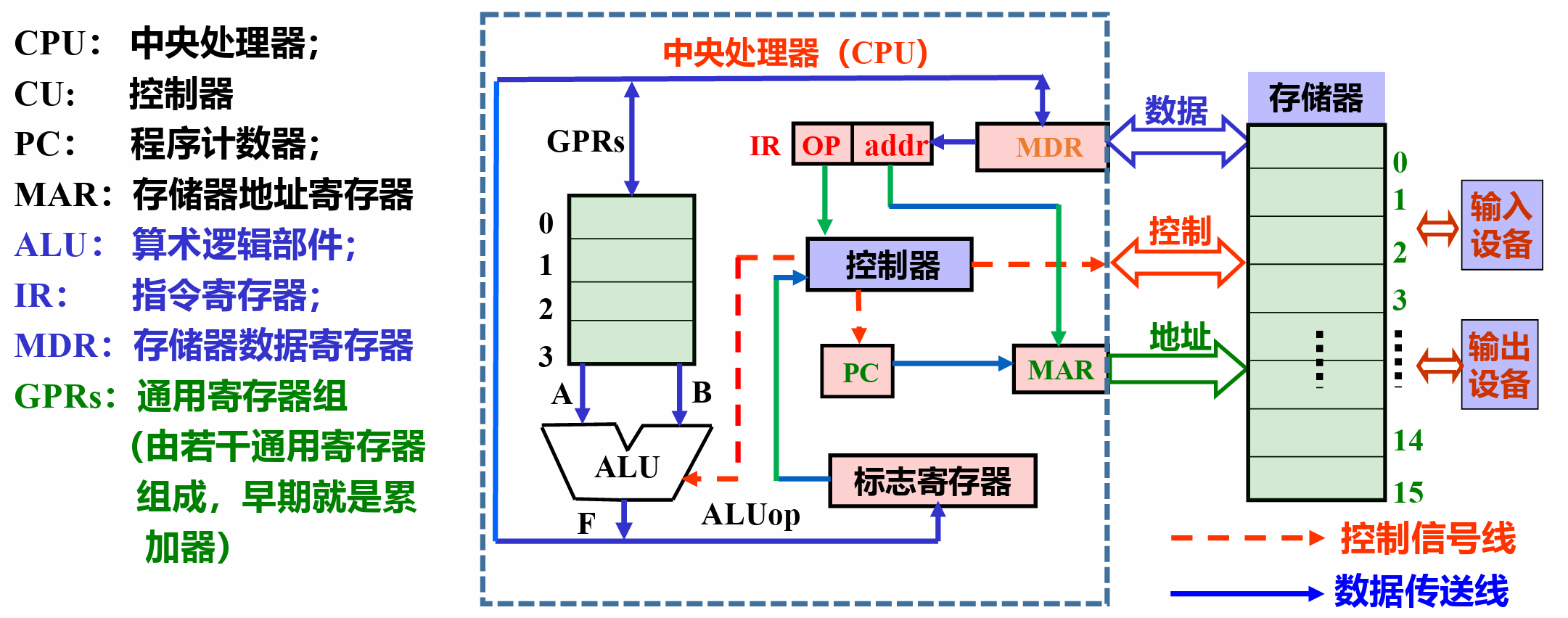
冯·诺依曼结构
- 基本思想:
- 采用"存储程序"工作方式
- 由
运算器,控制器,存储器,输入设备,输出设备五个基本部件组成 - 存储器不仅能放数据,还能放指令;形式上数据和指令没区别,但计算机能区分;控制器应能自动执行指令;运算器应能进行加减乘除四种基本算术运算,并且也能进行逻辑运算;操作人员通过输入/输出设备使用计算机
- 计算机内部以二进制形式表示指令和数据;每条指令由
操作码和地址码两部分组成,操作码指出操作类型,地址码指出操作数地址;由一串指令组成程序
- “存储程序”工作方式:任何要计算机完成的工作都要先被编写成程序,然后将程序和原始数据送入主存并启动执行。一旦程序被启动,计算机应能在不需操作人员干预下,自动完成逐条取出指令和执行指令的任 务。
- 基本结构(下图)
- 程序的执行过程
- 根据 PC 取指令
- 指令译码
- 取操作数并执行
- 回写结果
- PC 增量
程序设计语言
- 机器级语言:都属于低级语言,每条指令都与特定的机器结构相关
- 机器语言,机器代码:0/1 序列,每条指令都由 0/1 组成
- 汇编语言:用英文符号和机器指令建立对应关系,源程序需要转换为机器语言程序才能被执行
- 高级程序设计语言,高级编程语言:面向算法设计,与具体的机器结构无关
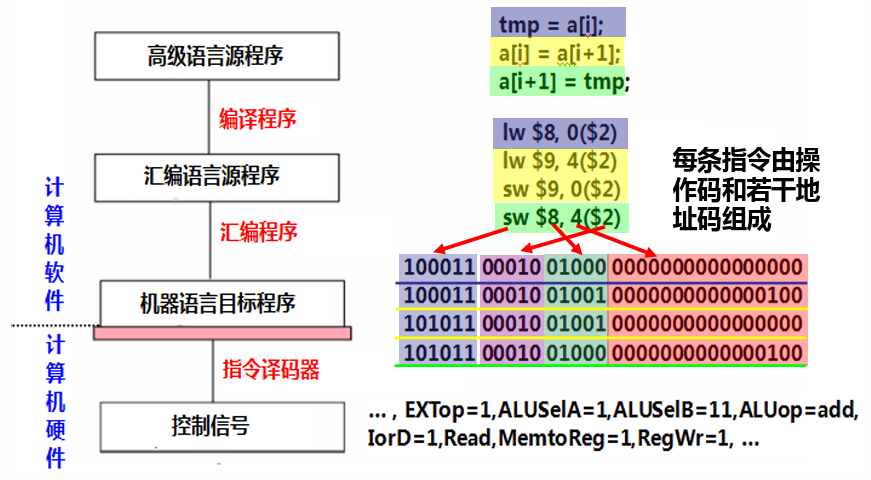
翻译程序
- 汇编程序,汇编器:汇编语言源程序 → 机器语言目标程序
- 解释程序,解释器:源程序逐条翻译成机器指令并立即执行
- 编译程序,编译器:高级语言源程序 → 汇编 / 机器语言目标程序
掌握等价转换?
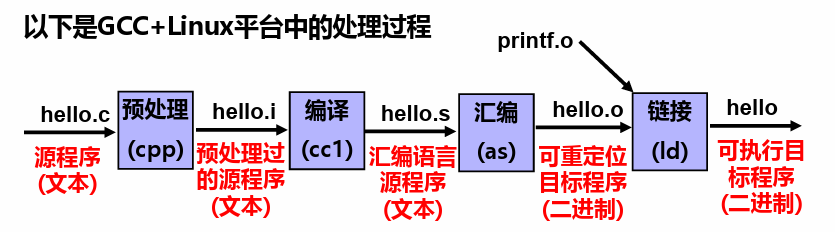
从源程序到可执行文件
- 编译阶段:编译程序(
cc1)对预处理后的源程序进行编译,生成一个汇编语言源程序,以.s为拓展名。 - 汇编阶段:汇编程序(
as)对汇编语言源程序进行汇编,生成一个可重定位目标文件,以.o为拓展名,是二进制文件,不可读。
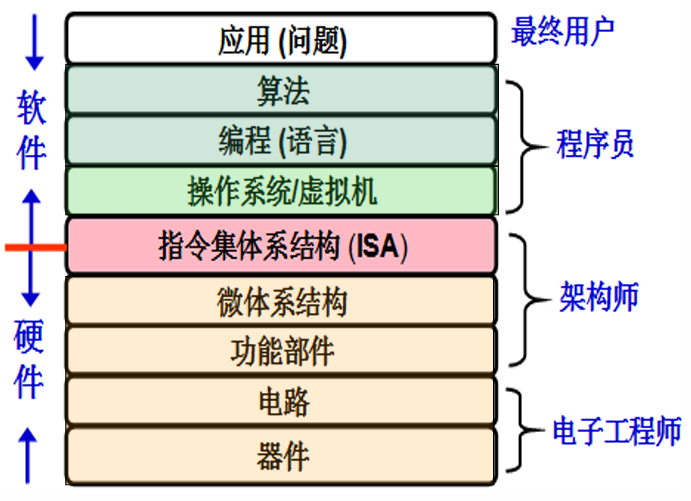
计算机系统的层次结构
- 指令集体系结构(ISA):是软件和硬件之间接口的一个完整定义,对指令系统的一种规范。内容包括:指令集、寄存器结构、存储空间和编址方式、数据存放方式、寻址方式、指令控制等。定义了一台计算机可以执行的所有指令的集合。
第二章
R 进制数和十进制数相互转换
- →,按权展开;
- ←,整数部分“除基取余”倒着写,小数部分“乘基取整”。
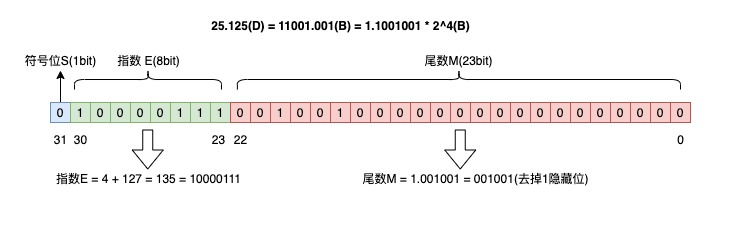
浮点数的表示(IEEE 754 标准)
掌握真值和机器码的转换。
- 标准浮点数的表示:

数据类型的宽度
| C 声明 | 32 位 (typ) | 64 位 |
|---|---|---|
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| long int | 4 | 8 |
| char* | 4 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
数据的基本运算
左移和右移
- 带符号使用算术移位,不考虑符号时使用逻辑移位。
- 溢出:左移可能产生溢出。对于无符号数,如果左移移出了 1,则溢出;对于有符号数,如果左移移出的位和新的符号位不同,则溢出。
- 截断:右移可能发生有效数据丢失。
整数加减运算
- 输出标志:(
表示进位输出, 是运算结果) - ZF,零标志:
ZF=1表示结果所有位都为 0,否则为 1; - OF,溢出标志:同号相加符号位不变,否则溢出。即
。 - SF,符号标志:即结果的符号位。
- CF,进 / 借位标志:加法若结果有进位,则为 1;减法若不够减,则为 1。即
。
- ZF,零标志:
常量的乘除运算
- 使用移位、加法和减法的运算代替乘法运算能省时钟周期。一次乘法运算需要 10 个左右时钟周期,一次除法运算需要 30 个或更多时钟周期。
掌握计算省下了多少时钟周期?
浮点数加减运算
- 对阶:阶小的数右移,隐含的 1 需要被移出,空出的位补 0。移出的位不丢,参与运算,保证精度。
- 尾数加减:是原码运算,隐含的 1 和右移的附加位也参与运算。
- 尾数规格化
- 尾数舍入:中间结果右边至少保留两位。第一位为保护位,用于保护右移的位;第二位为舍入位,用于舍入。进一步提高计算精度,还引入粘位,只要舍入位右边还有数字,粘位被置 1。(IEEE 754)
- 就近舍入到偶数(0 舍 1 入):
- 朝
方向舍入。 - 朝
方向舍入。 - 朝
方向舍入。
- 就近舍入到偶数(0 舍 1 入):
- 阶码溢出判断:若右规后阶码全
,则发生阶码上溢,产生异常或可能被置为 或 ;若左规后阶码全 ,则发生阶码下溢,结果为非规格化形式。
浮点数乘除运算
和加减类似,但在进行运算前需要保证操作数为两个正常的规格化浮点数,计算步骤中不需要对阶。
需要注意的例题和课后题
- 大端、小端,数据在内存中存放的方式
- P33,进制转换
- P48,例 2.23,例 2.24
- P75,例 2.36
- 课后题 9,23,24,28,34,35
第三章
课本的 RTL 规定:R[r] 表示寄存器的内容,M[addr] 表示存储单元addr的内容,寄存器r采用不带M[PC]表示PC所指存储单元的内容;M[R[r]]表示寄存器r的内容所指的存储单元的内容。传送方向用 ← 表示。
不是重点,怕看混了
数据类型及其格式
| C 声明 | Intel 操作数类型 | 汇编指令长度后缀 | 存储长度(位)(IA-32) |
|---|---|---|---|
| (unsigned) char | 整数/字节 | b | 8 |
| (unsigned) short | 整数/字 | w | 16 |
| (unsigned) int | 整数/双字 | l | 32 |
| (unsigned) long int | 整数/双字 | l | 32 |
| (unsigned) long long int | — | — | 2 × 32 |
| char* | 整数/双字 | 4 | 32 |
| float | 单精度浮点数 | s | 32 |
| double | 双精度浮点数 | l | 64 |
| long double | 扩展精度浮点数 | t | 80 / 96 |
IA-32 常用指令
通用数据传送指令
传送寄存器或存储器中的数据。
MOV:movb,movw,movlMOVS:符号拓展传送指令,比如movsbw表示符号拓展s一个字节b数据后传送到一个字w地址中。MOVZ:零拓展传送指令。
栈:高地址向低地址增长,使用 ESP 寄存器(stack pointer)指向栈顶。
PUSH:先执行R[sp] <- R[sp] - 2(字)或R[esp] <- R[esp] - 4(双字),然后将一个字或者双字从指定寄存器送到 SP 或 ESP 指示的栈单元中。如pushl表示双字压栈,pushw表示字压栈。POP:先将一个字或双字从 SP 或 ESP 指示的栈单元送到指定寄存器中,再执行R[sp] <- R[sp] + 2(字)或R[esp] <- R[esp] + 4(双字)。如popl表示双字出栈,popw表示字出栈。
地址传送指令
传送源操作数的地址,指定目的寄存器不能是段寄存器,且源操作数必须是存储器寻址方式。可以利用该指令进行运算。
LEA(load effective address)

定点算术运算指令
CMP:目的操作数减源操作数(AT&T 右减左),只改变标志位
下面这四条只是怕忘蒽…
INC:加 1,包括incb、incw、incl等DEC:减 1,包括decb、decw、decl等MUL/IMUL:无符号乘 / 带符号乘DIV/IDIV:带无符号除 / 带符号除。指令中只明显指出除数,使用AL / AX / EAX中的内容除以除数。
按位运算指令
仅NOT 不影响条件标志位,其余指令执行后,
TEST:两操作数相与,不改变原操作数。
移位指令
SHL/SHR: 逻辑左/右移(无符号),包括shlb、shrw、shrl等SAL/SAR: 算术左/右移(带符号),左移判溢出,右移高位补符,包括salb、sarw、sarl等(移位前、后符号位发生变化,则) ROL/ROR:循环左/右移,包括rolb、rorw、roll等RCL/RCR: 带进位循环左/右移,即:将作为操作数一部分循环移位,包括 rclb、rcrw、rcll等
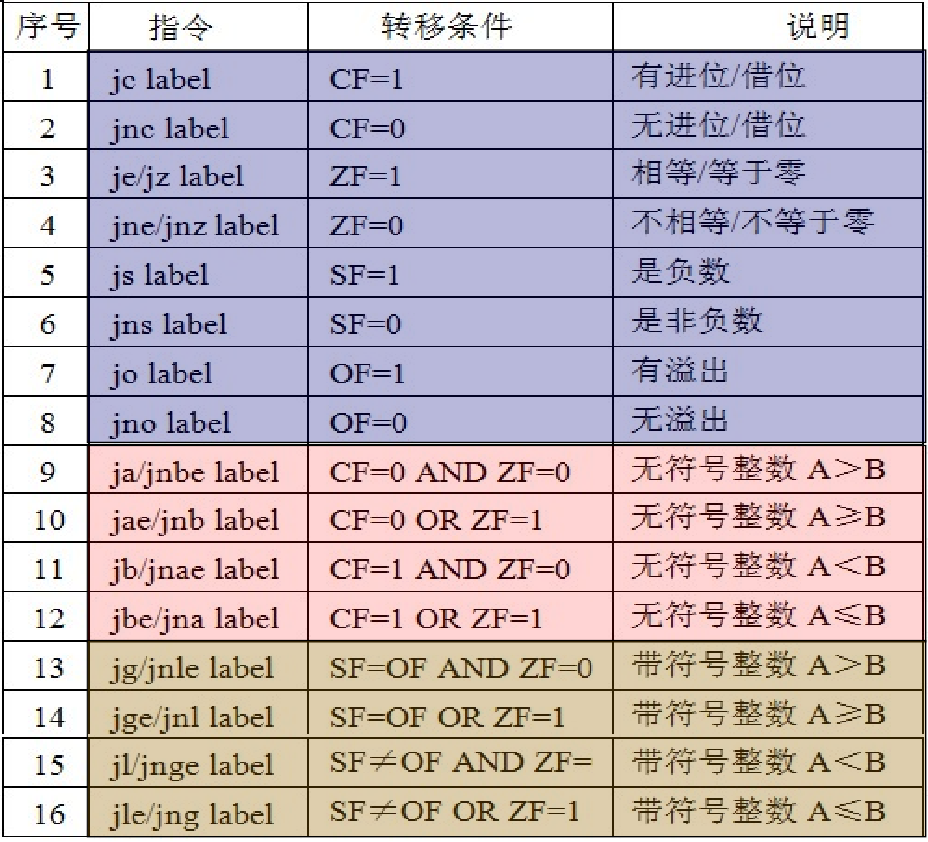
控制转移指令
四个标志位c、z、s、o;相等e;无符号数a(above)、b(below);有符号数g(greater)、l(less)。
C 语言程序的机器级表示
过程调用的执行步骤(P 为调用者,Q 为被调用者)
现场即通用寄存器的内容。
- P 保存现场(必要时);
- 将入口参数(实参)放到 Q 能访问到的地方;
- P 保存返回地址,然后将控制转移到 Q;(
CALL)
以上三步为 P 栈帧。
- Q 保存 P 的现场,并为自己的非静态局部变量分配空间;(准备阶段)
- 执行 Q 的过程体(函数体);(处理阶段)
- Q 恢复 P 的现场,释放局部变量空间;
- Q 取出返回地址,将控制转移到 P。(
RET)
以上四步为 Q 栈帧。
IA-32 的寄存器使用约定
调用者保存寄存器:
eax,edx,ecx如果调用函数 P 调用完 Q 返回后,还需用到
eax寄存器,则需要 P 在调用 Q 前保存。一般而言 P 调用 Q 之后不需要用到eax寄存器,所以一般会将操作数优先存在eax,edx,ecx这类寄存器,以被调用者保存寄存器:
ebx,esi,edi如果被调用者 Q 需要用到
ebx,则 Q 需要保存到栈中再使用。ebp:帧指针寄存器,指向当前栈帧底部,高地址esp:栈指针寄存器,指向当前栈帧顶部,低地址。
为减少准备和结束阶段的开销,每个过程应先使用eax,edx,ecx寄存器。
栈、栈帧
栈:高地址向低地址增长,使用 ESP 寄存器(stack pointer)指向栈顶。
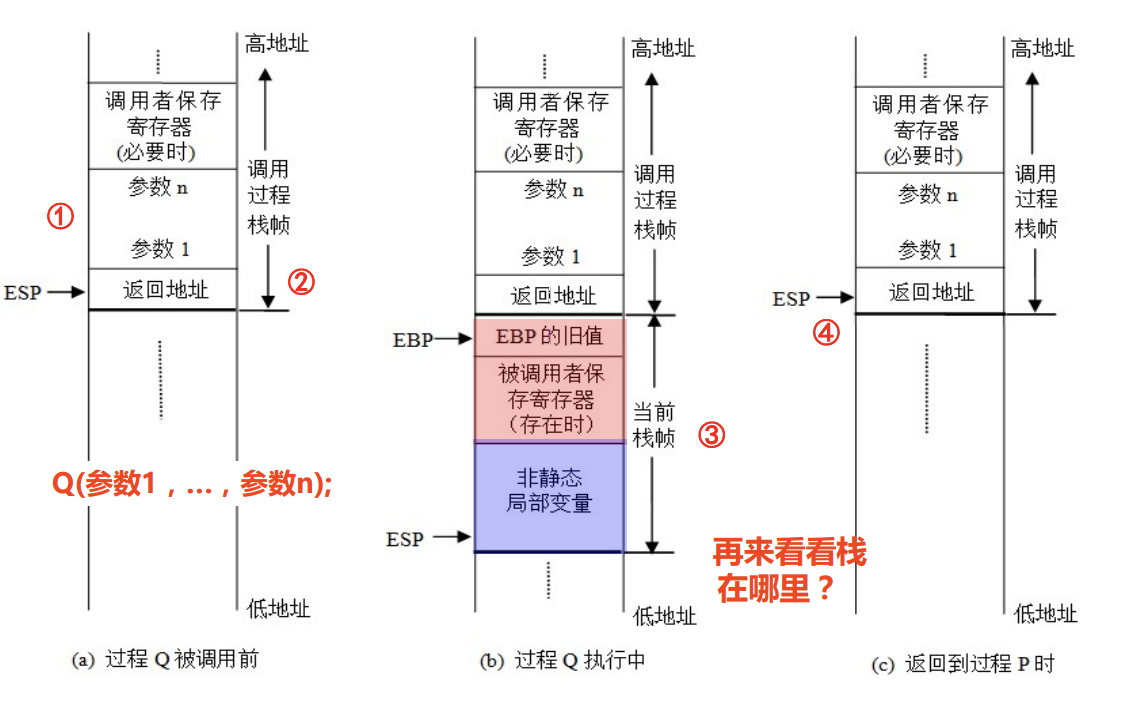
返回地址就是call 指令的下一条指令的地址。

变量的作用域和生存期
Q 栈帧中保存的 Q 内部的非静态局部变量只在 Q 执行过程中有效。
结合栈的图
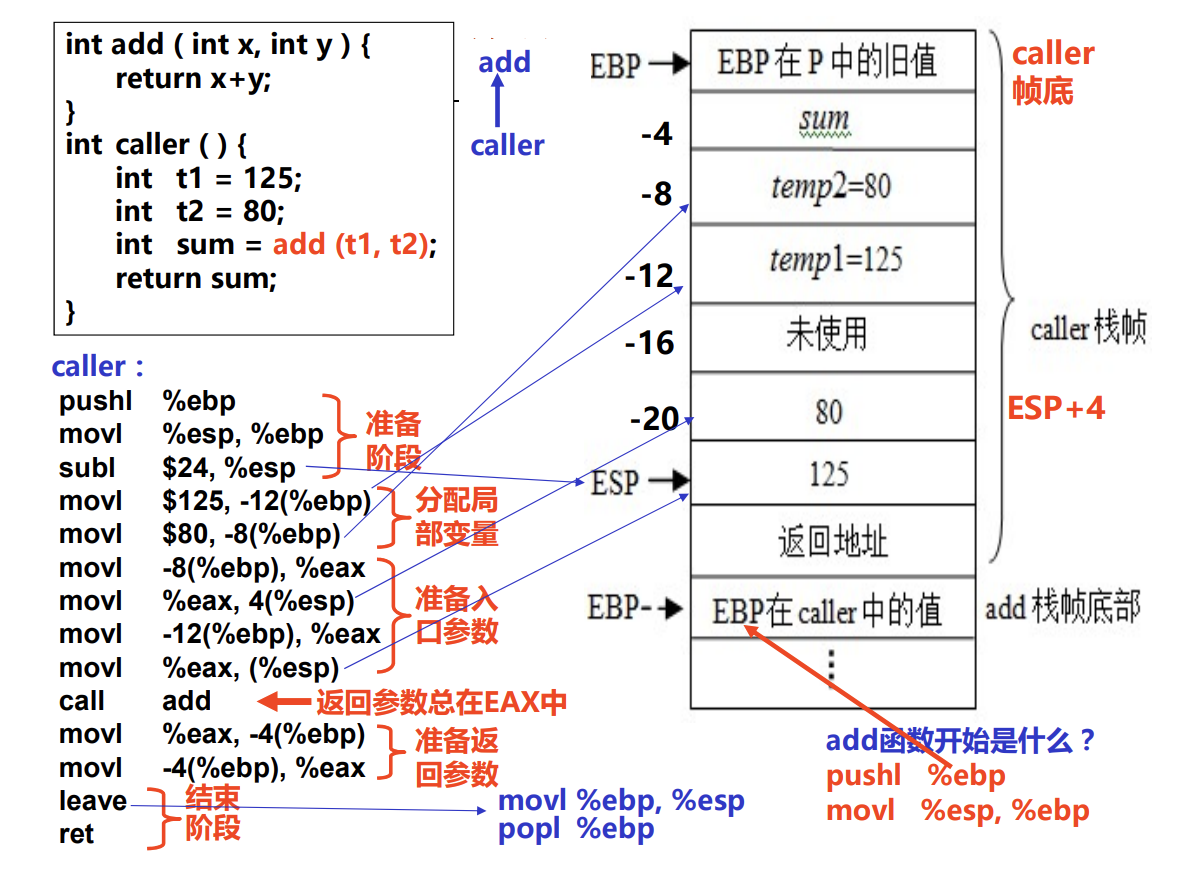
准备参数入口,将值再复制了一遍是为什么? 假设回调函数为
swap(&t1,&t2),要改变局部变量的之前是不是得先存起来,不然令t1=t2,t1 原来的值消失了怎么办。
按值传递参数和按地址传递参数
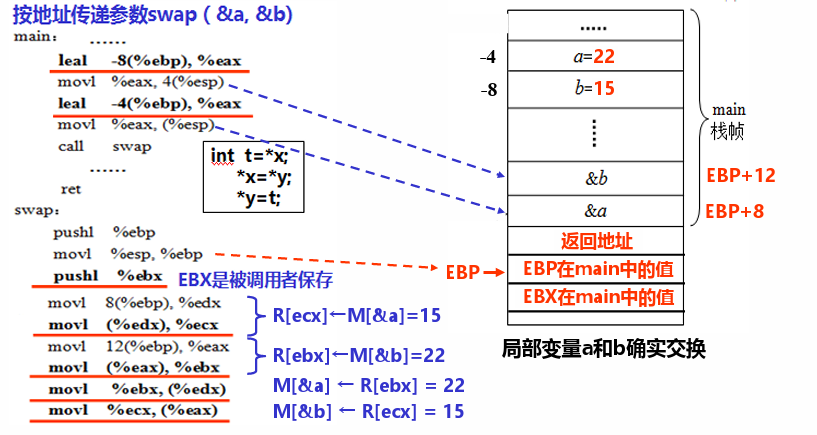
i386 中栈数据按 4 字节对齐,所以入口参数地址是R[ebp]+8 、R[ebp]+12 、R[ebp]+16 等等。R[ebp]+4 是返回地址。
复杂数据类型的分配和访问
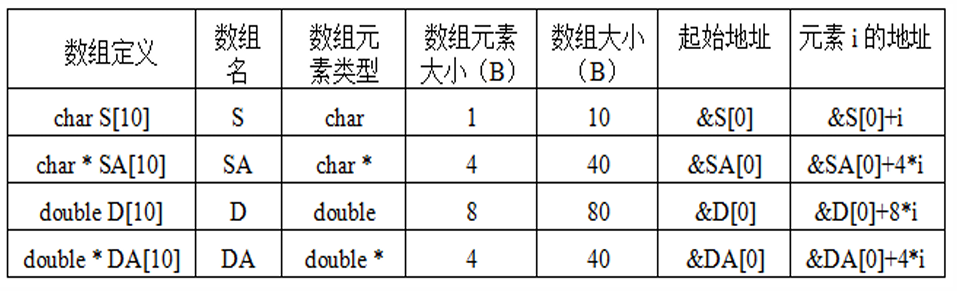
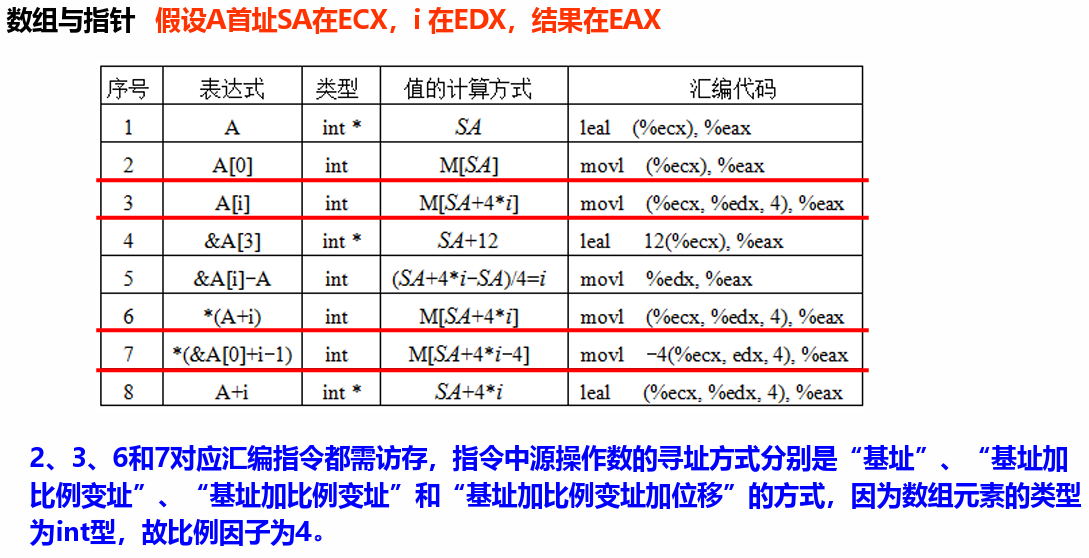
数组
例如,static short A[4];要访问第i个元素,使用汇编指令movw (%edx, %ecx, 2), %ax 。由于是short类型,所以比例因子是 2(2 字节,1 字)。其中,ECX为变址(索引)寄存器,在循环体中增量。
数组与指针
结构体
结构型变量 x 各成员首址可用“基址加偏移量”的寻址方式。

数据的对齐
最简单的对齐策略是,按其数据长度进行对齐,例如,int型地址是 4 的倍数,short型地址是 2 的倍数,double和long long型的是 8 的倍数,float型的是 4 的倍数,char不对齐。Windows 采用该策略。
有用的小 trick:
- 前面的地址必须是后面的地址正数倍,不是就补齐
- 整个
struct的地址必须是最大字节的整数倍
x86-64
基本特点
- 字长从 32 位变为 64 位,64 位(8B)数据被称为一个四字(
qw: quadword)。指针(char*)和长整型(long)数据从 32 位拓展到 64 位。 long double型数据虽然还采用 80 位(10B)扩展精度 格式,但所分配存储空间从 12B 扩展为 16B,即改为 16B 对齐方式,但不管是分配 12B 还是 16B,都只用到 低 10B。
需要注意的例题和课后题
例如
pushlpoplleal等指令执行过程理解
cmpl加条件转移指令的理解汇编上机实验内容的编写理解
IA-32 与 X86-64 的区别
根据汇编写出 C 代码
- P105,例 3.3
- P122,7;P124,8
- P150,例 3.14
- 课后题,6,8,10,11,14,17,19,21,22,23,28
汇编实验
CODE SEGMENT
ASSUME CS:CODE
Begin: MOV BX,0 ; BX用于存放四位的16进制数
MOV CH,4 ; CH用于计数,表示还需要输入的字符个数
MOV CL,4 ; CL用于循环计数,表示每次输入一个字符后,BX左移的位数
INPUT: SHL BX,CL ; 将BX左移CL位,为下一个字符的腾出位置
MOV AH,1 ; 调用INT 21H中的功能1,从标准输入获取一个字符
INT 21H
CMP AL,30H ; 比较输入的字符是否小于 '0'
JB INPUT ; 如果小于 '0',重新输入
CMP AL,39H ; 比较输入的字符是否大于 '9'
JA AF ; 如果大于 '9',跳转到AF处理字母输入
AND AL,0FH ; 将字符转换为对应的数字
JMP BINARY ; 跳转到BINARY继续处理
AF: AND AL,11011111B ; 处理字母输入,将大写字母转换为小写
CMP AL, 'A' ; 比较是否小于 'A'
JB BINARY ; 如果小于 'A',跳转到BINARY继续处理
SUB AL, 'A' - 10 ; 将字母转换为对应的数字
BINARY: OR BL,AL ; 将处理后的数字与BX寄存器中的内容进行"或"运算
DEC CH ; 计数减一
JNZ INPUT ; 如果计数不为零,继续输入下一个字符
NEXT: MOV CX,16 ; 初始化循环计数器CX,用于循环输出二进制数的每一位
DISP: MOV DL,0 ; 初始化DL,用于存储二进制数的每一位
ROL BX,1 ; 将BX左循环移位,将最高位移入Carry Flag中
RCL DL,1 ; 将Carry Flag中的值存入DL,相当于取得BX最低位的值
OR DL,30H ; 将DL转换为ASCII码表示的字符
MOV AH,2 ; 调用INT 21H中的功能2,输出一个字符
INT 21H
LOOP DISP ; 循环,输出下一位二进制数
STOP: MOV AH, 4CH ; 调用INT 21H中的功能4CH,程序结束
INT 21H
CODE ENDS
END Begin(代码注释由 ChatGPT 生成)
- 主要看
INPUT和AF部分,INPUT部分是输入,AF部分是处理字母输入,将大写字母转换为小写,然后再转换为对应的数字。