
实验 3:卷积神经网络
一、实验内容
MNIST 数据集分类
MNIST 数据集是一个手写数字数据集,包含 0-9 的数字图片,每张图片大小为 28x28,在早期的深度学习领域被广泛使用。按照文档要求,使用 PyTorch 搭建一个简单的卷积神经网络,对 MNIST 数据集进行分类。
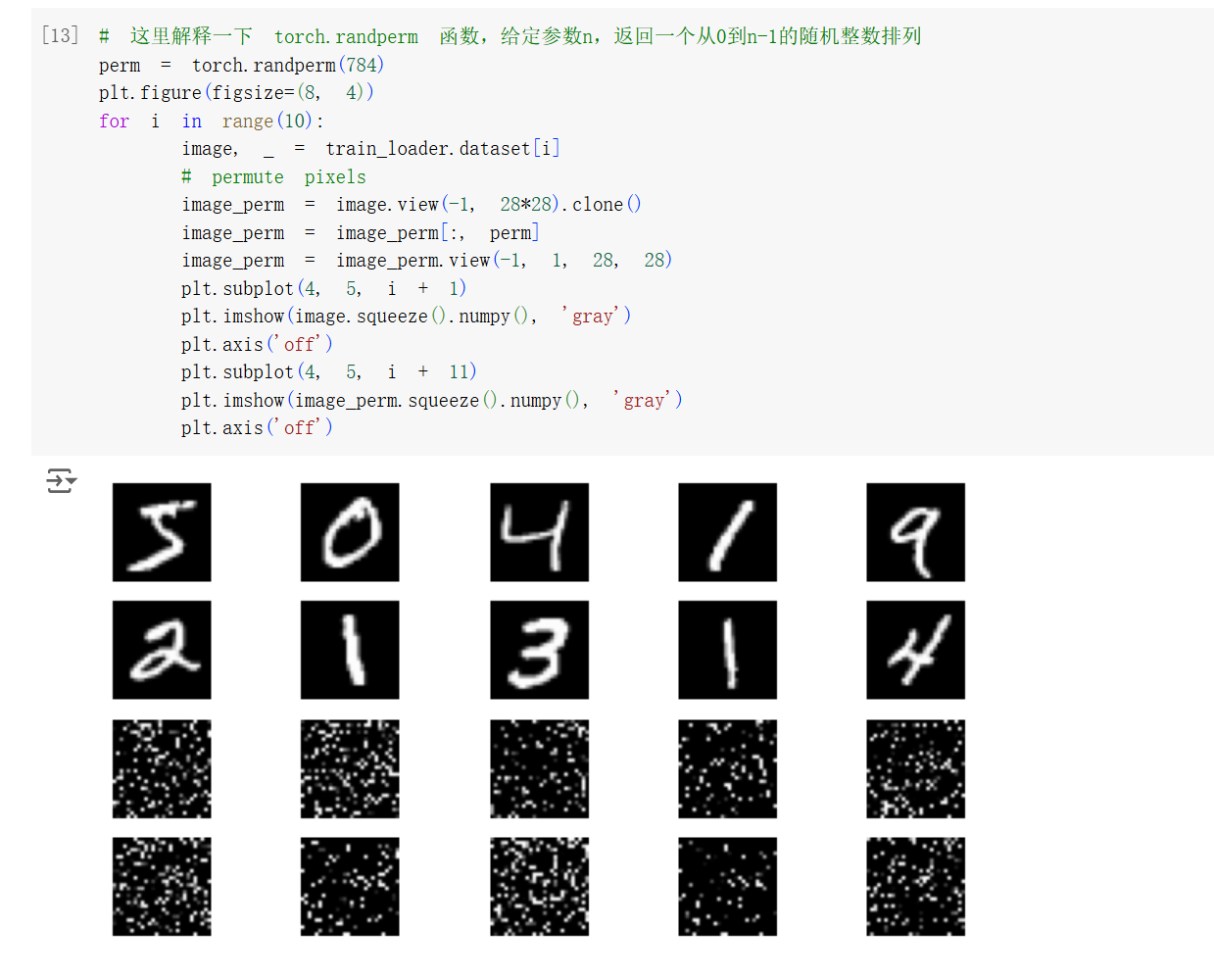
对数据集的数据进行可视化,可以看到数据集中包含了 0-9 的手写数字图片。其中许多写法更偏向欧美的书写习惯,和咱们的习惯相比有些不同。通过调用 torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False) 函数,可以加载 MNIST 数据集。 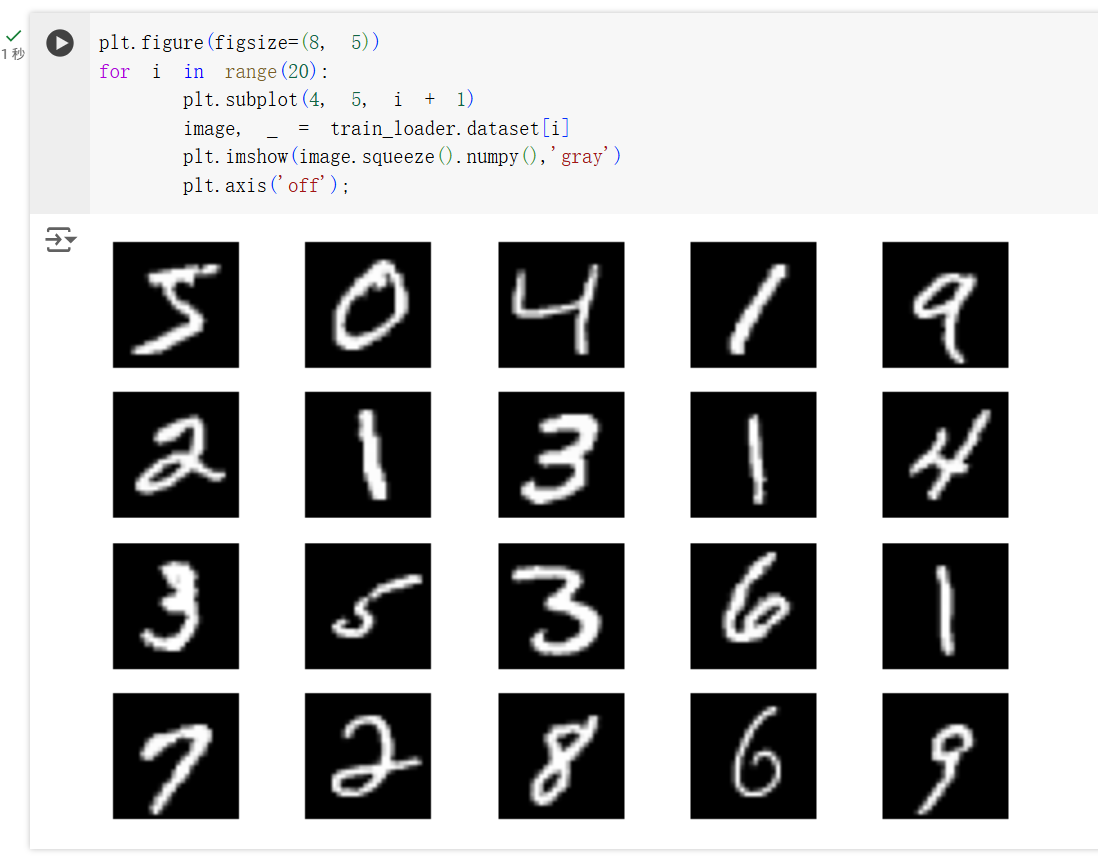
文档中分别给出了使用全连接层的结构和卷积层的结构,可以看到相似的参数量下,卷积层的准确率更高。这是因为卷积层可以提取图像的局部特征,更适合处理图像数据。在卷积层中,使用了卷积层、池化层、激活函数、全连接层等结构,通过这些结构可以提取图像的特征,从而提高模型的准确率。
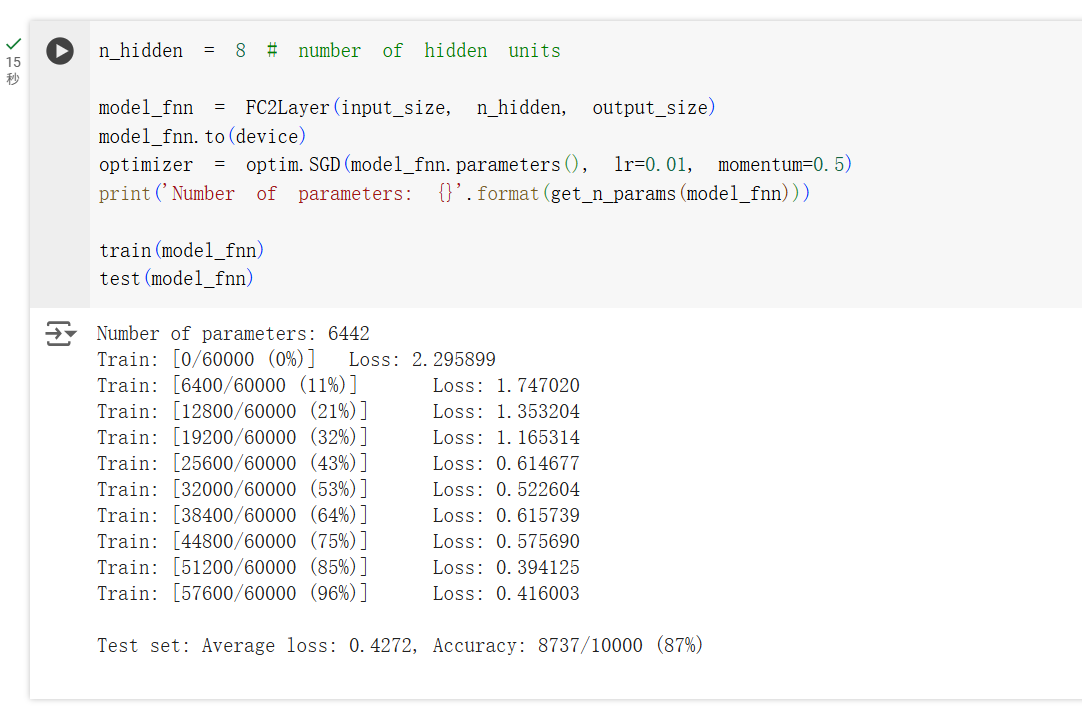
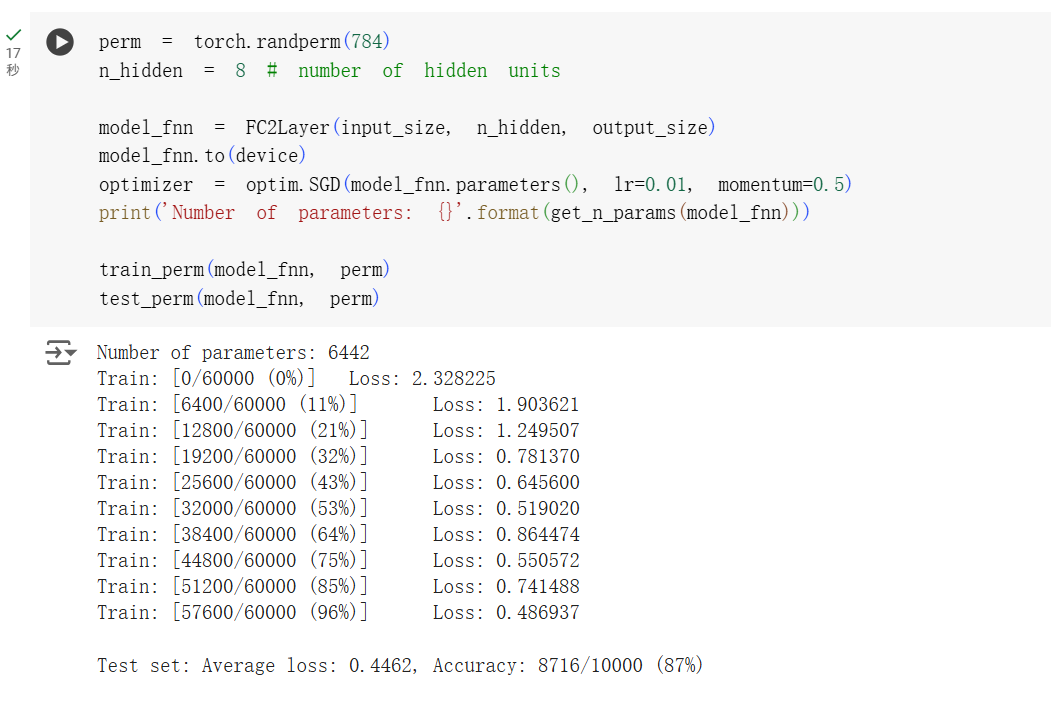
上图是全连接层的结构训练出来的准确率,仅有 87% 左右。
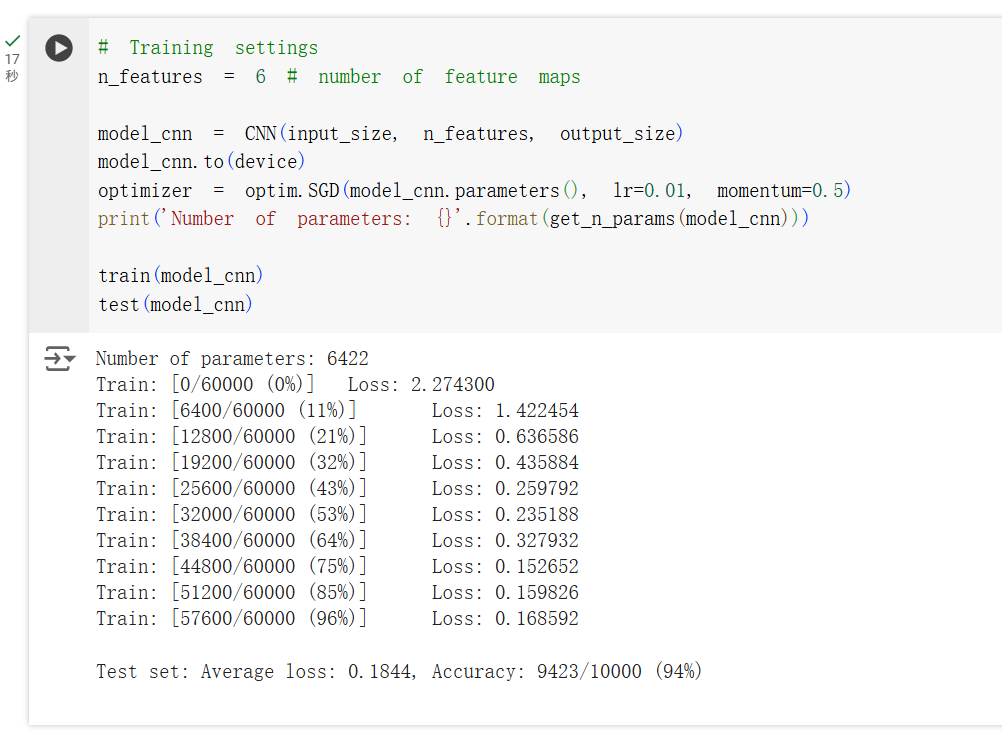
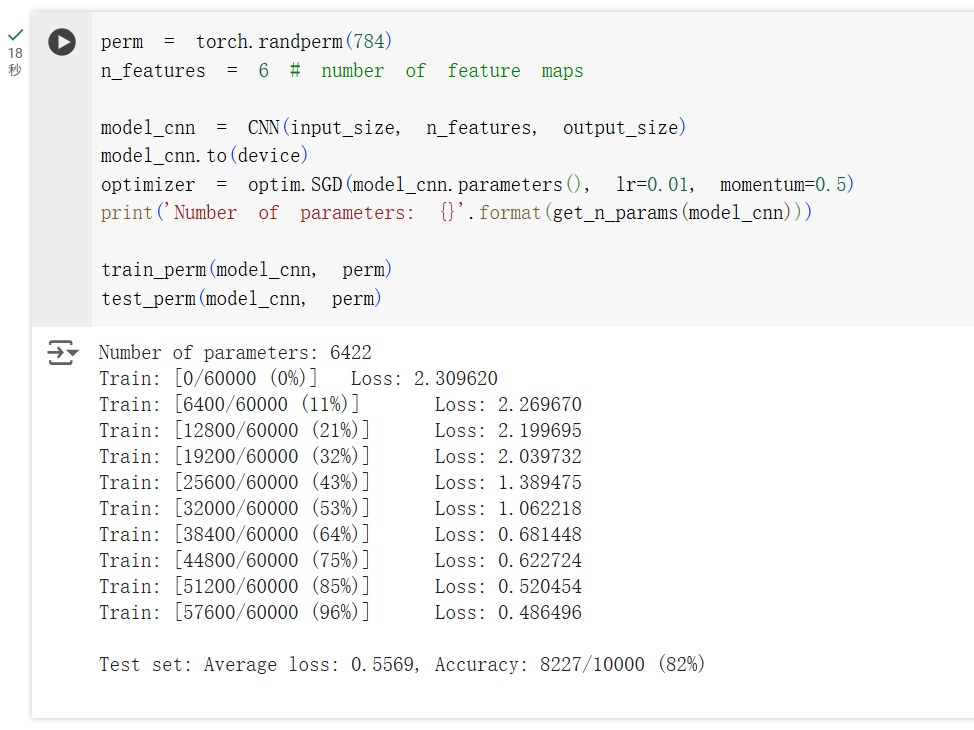
对于卷积层的结构,训练出来的准确率可以达到 94% 左右。
为了找到其中提升的原因,文档另外设计了打乱像素点的顺序的实验,可以看到打乱像素点的顺序后,准确率下降了。这是因为打乱像素点的顺序后,模型学习到的特征被破坏了,导致模型的准确率下降。而全连接层并不受像素点顺序的影响,仅仅只是对像素点进行线性变换,所以准确率不受影响。
先打印一下 shape,可以看到每个 batch 的数据有 64x784 的大小,784 是 28x28 的大小,64 是 batch_size 的大小。
下图是打乱像素点顺序后的准确率,可以看到全连接层的准确率并没有下降。
而卷积模型的准确率下降到了 82% 左右。对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR-10 数据集分类
CIFAR-10 是一个 10 分类的图像数据集,包含了飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车等 10 个类别的图片。CIFAR-10 数据集的图片大小为 32x32,是一个更加复杂的数据集。
首先先构建一个简单的有两层卷积层的网络,使用交叉熵损失函数和 Adam 优化器,对 CIFAR-10 数据集进行分类。
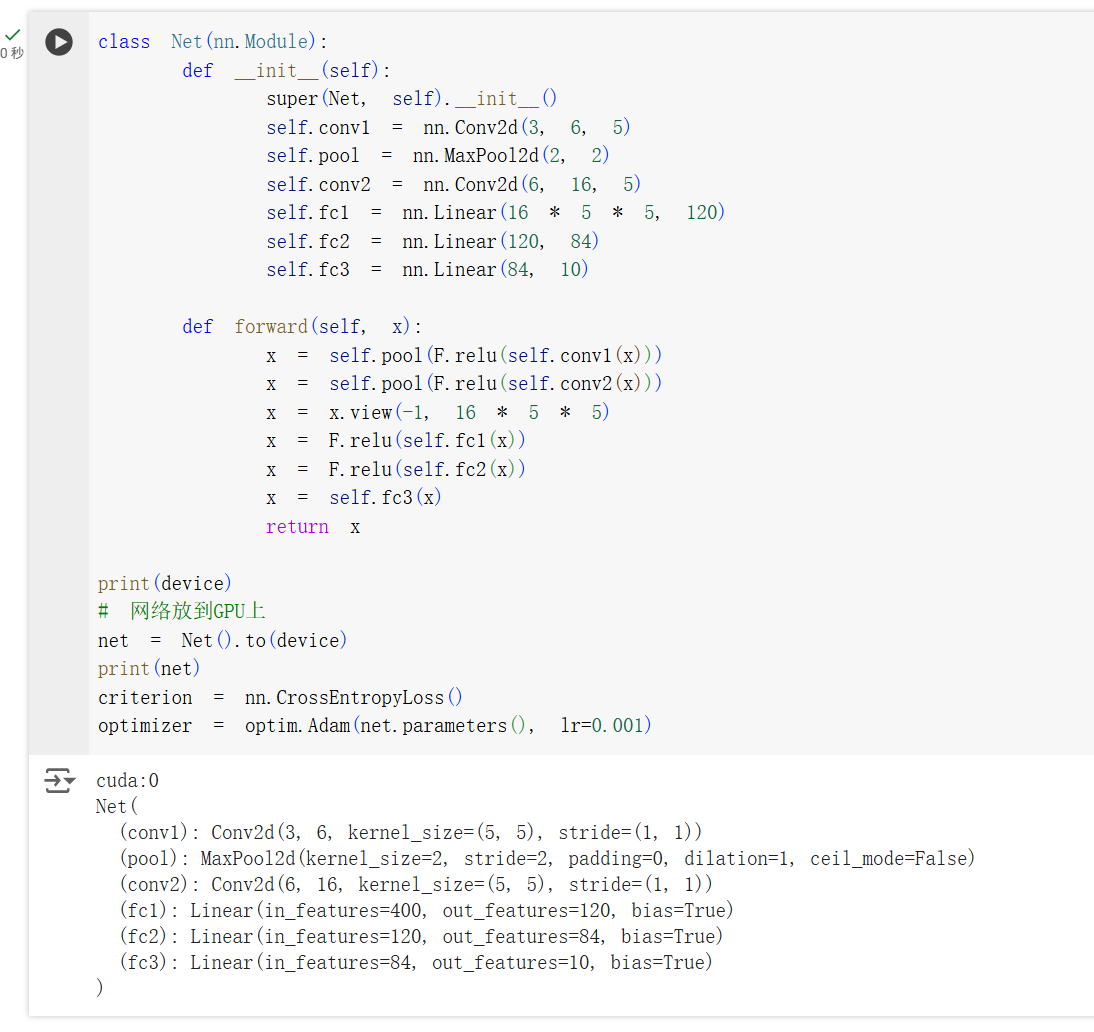
训练后抽出一些图片进行预测,可以看到模型的预测结果和真实结果有一定的差距。
模型把第四张的飞机认成了船。

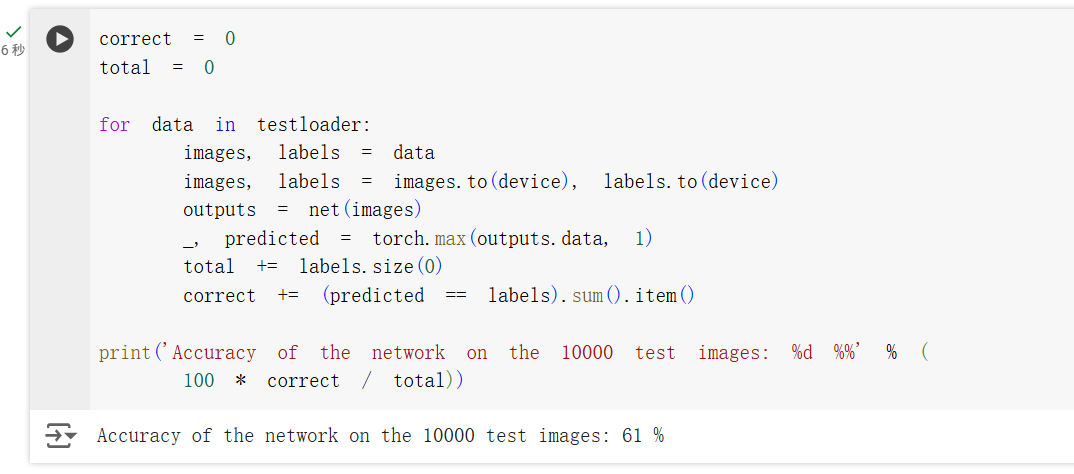
在整体的准确率上,可以看到模型的准确率在 61% 左右,这个准确率并不是很高。
使⽤ VGG16 对 CIFAR10 分类
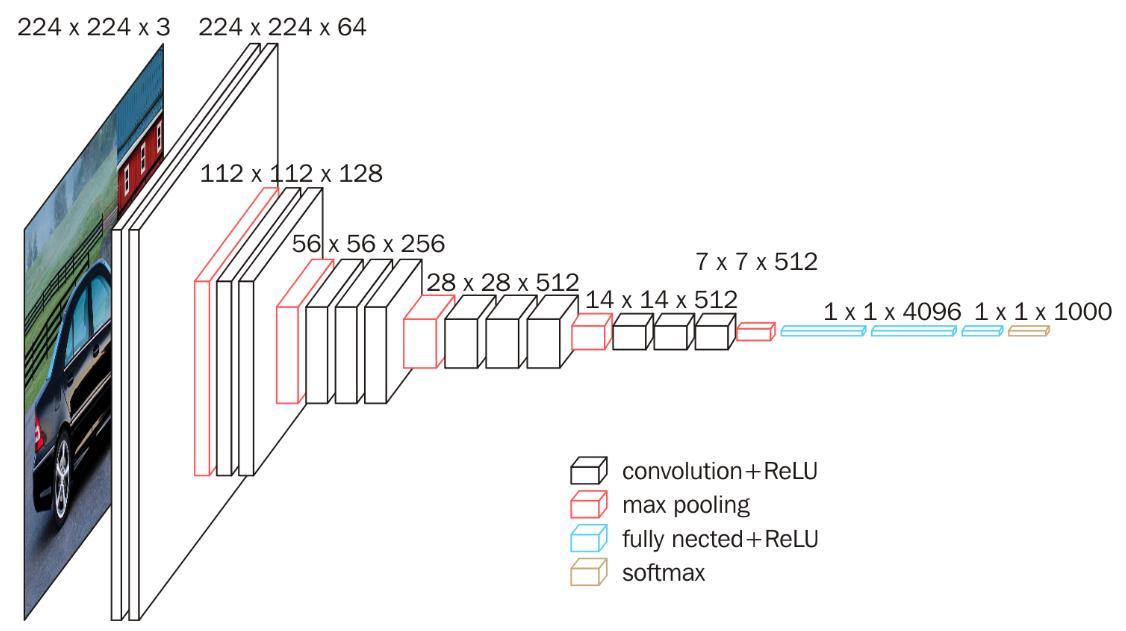
VGG16 是一个比较经典的卷积神经网络,它的结构比较简单,但是效果很好。VGG16 有 13 个卷积层和 3 个全连接层,它将普通的卷积层和池化层堆叠在一起,形成了一个深度较深的网络。VGG16 的结构如上图所示。
数据预处理这里使用了 transforms.Compose 对数据进行了一系列的变换,包括了随机裁剪、随机翻转、归一化等操作。然后使用 DataLoader 对数据进行加载。值得一提的是这里的 Normalize 使用了几个固定的值,查了一下,这几个值是 CIFAR-10 数据集的均值和标准差,和之前使用的 0.5 相比,这样可以更好地对数据进行归一化。
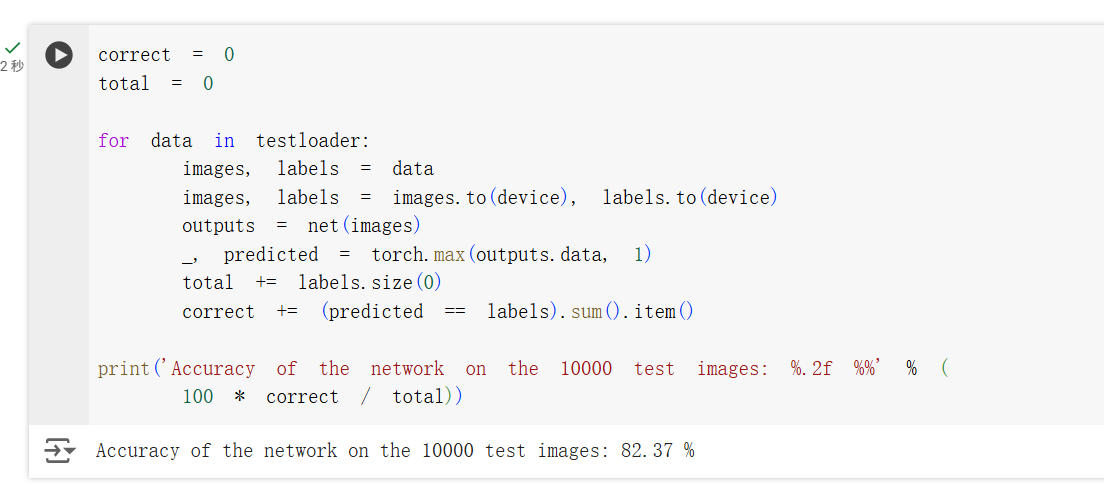
可以看到,使用一个简化版的 VGG 网络,就能够显著地提高模型的准确率,达到了 82.37% 左右。原因还是在于更深的网络结构可以提取更多的特征,从而提高模型的准确率。尽管更深的网络结构会增加训练的时间、可能导致梯度消失等问题,但是也有许多方法可以解决这些问题,比如使用残差网络、使用更好的优化器等。
二、问题总结与体会
思考题
dataloader ⾥⾯ shuffle 取不同值有什么区别?
shuffle=True 时,每个 epoch 都会打乱数据集的顺序,这样可以增加模型的泛化能力,因为每个 epoch 都会看到不同的数据,从而减少过拟合的可能性。
transform ⾥,取了不同值,这个有什么区别?
变换数据、进行数据增强,扩充数据集,增加模型的泛化能力。
epoch 和 batch 的区别?
epoch 是指整个数据集被训练了一次,batch 是指每轮训练时模型看到的数据量。
1x1 的卷积和 FC 有什么区别?主要起什么作⽤?
1x1 的卷积和全连接层的区别在于 1x1 的卷积是对每个像素点进行卷积,而全连接层是对整个图片进行线性变换。在许多地方,1x1 的卷积可以替代全连接层;同时 1x1 卷积也被用于升维和降维,可以增加模型的非线性,提高模型的准确率。
residual leanring 为什么能够提升准确率?
残差学习将 x 与 F(x) 相加,使得模型可以学习直接对残差进行学习,有利于学习到微小的特征,提高模型的准确率。
代码练习⼆⾥,⽹络和 1989 年 Lecun 提出的 LeNet 有什么区别?
代码练习二使用了简单的 CNN 网络,和 LeNet 相比:
- 激活函数的选择不一样,LeNet 使用的是 sigmoid 激活函数,而代码练习二使用的是 ReLU 激活函数。
- 使用最大值池化替代了平均值池化。
这个网络更像是简化版的 AlexNet。
代码练习⼆⾥,卷积以后 feature map 尺⼨会变⼩,如何应⽤ Residual Learning?
可以对残差块进行下采样,使得残差块的输出尺寸和输入尺寸一致。
有什么⽅法可以进⼀步提升准确率?
可以使用 ResNet 等更深的网络,增加网络的深度,提高模型的准确率。或者使用 Transformer 等更先进的网络结构以获得更好的性能。
遇到的问题
在处理图像时,Colab 显示在
iter(trainloader).next()处报错 AttributeError: '_MultiProcessingDataLoaderIter' object has no attribute 'next'。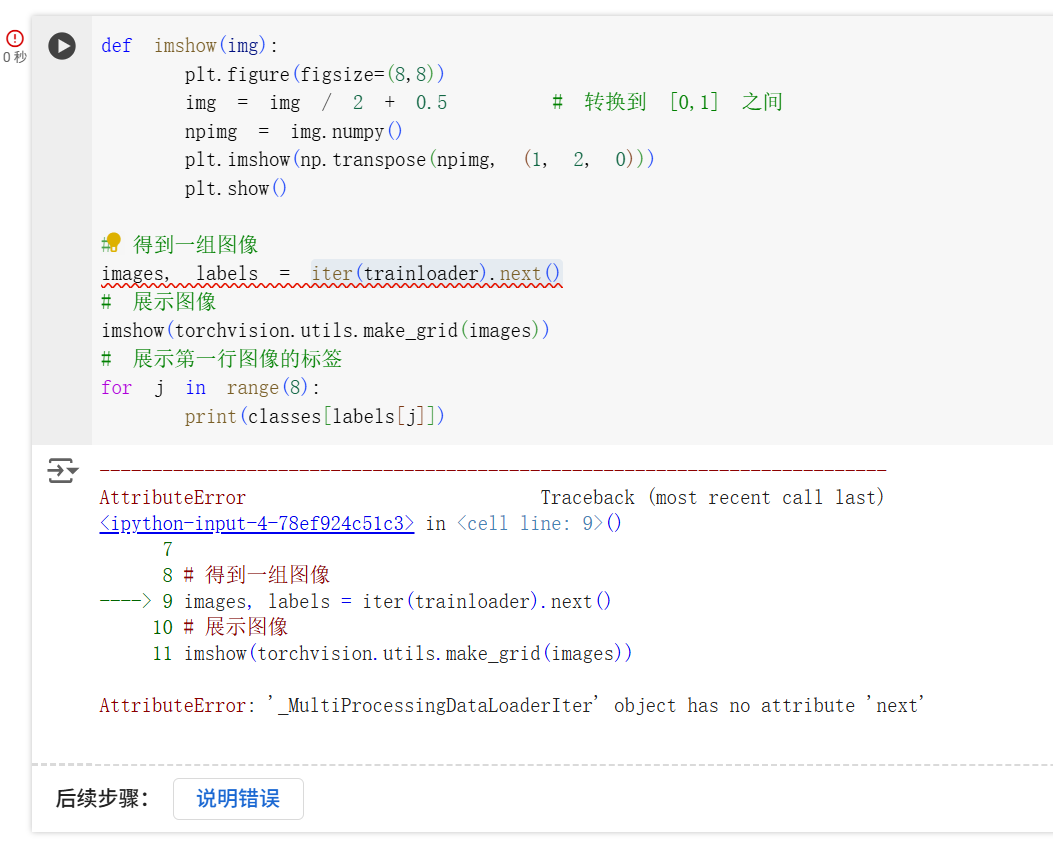
这是因为在 Colab 中使用多进程加载数据集时,不能使用
iter(trainloader).next(),而应该使用next(iter(trainloader))。
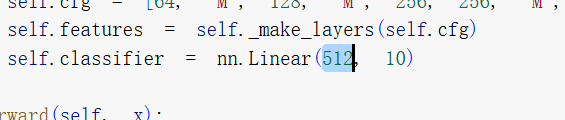
在最后一个实验中,shape 不匹配导致无法训练。
打印模型结构发现 VGG 前向传播里最后一个输出的分类器(全连接层)应该有 1x10 的输出,因为上一层传下来的就是展平后大小为 512 的数据,所以输入应该是 512,改正后可以正常训练。
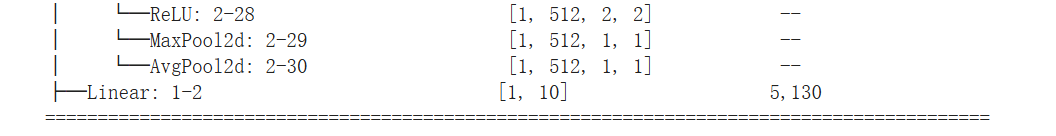
体会
国庆假期归来再来接着写一周前的作业,幸好实验探究的内容之前有了解过,再做起来就不是很难了。