
实验 4:MobileNet & ShuffleNet
一、实验内容
MobileNet
MobileNet 是 Google 用于移动设备的视觉分类模型,既然要用在移动设备上,自然参数量不能太大,否则模型的效率就会很低。如何在参数量和网络效果上作权衡?它使用了深度可分离卷积这一概念来构建轻量模型。
V1
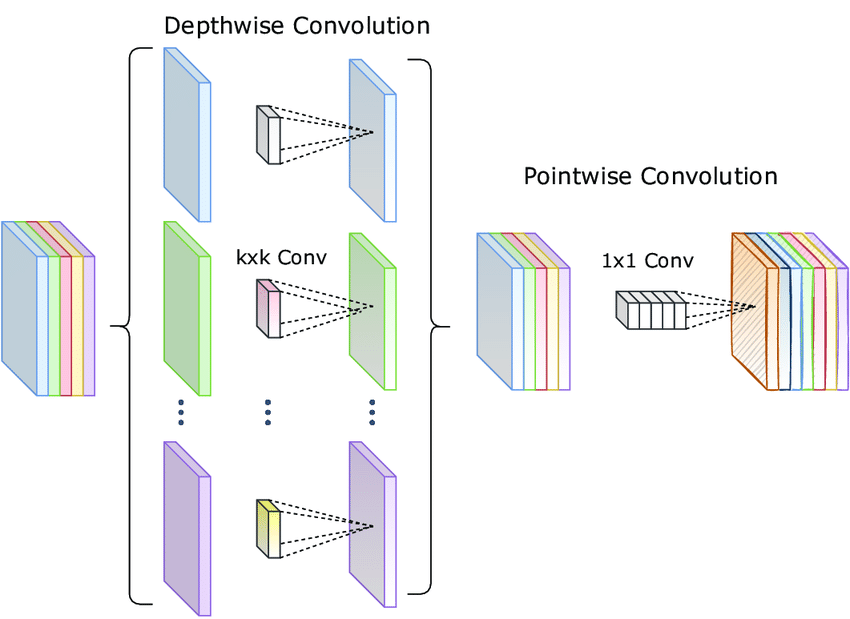
所谓深度可分离,就是说把卷积核的深度和空间维度分开,从而达到降低复杂度的目的。不分离的时候,需要几个输出通道,就需要几个卷积核,每个卷积核都要对各个深度进行卷积然后求和,参数量大约是
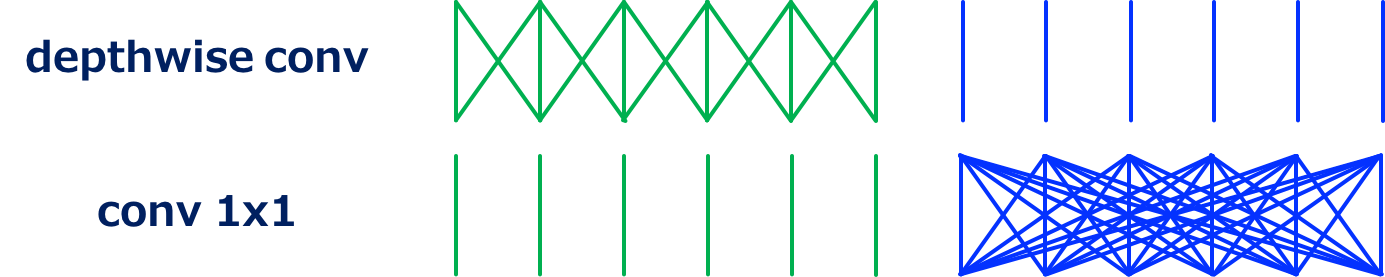
深度卷积,就是让卷积核的作用范围从各个深度维度变成单个深度维度,这样就能将第一步的参数量降到
V2
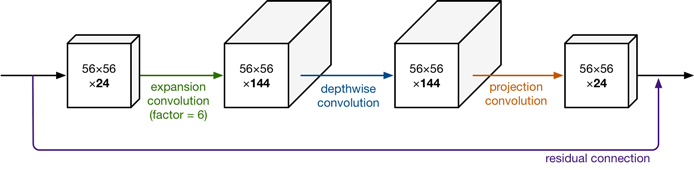
V2 相比较 V1 主要的改进就是加入了残差机制,和延展、投影处理。
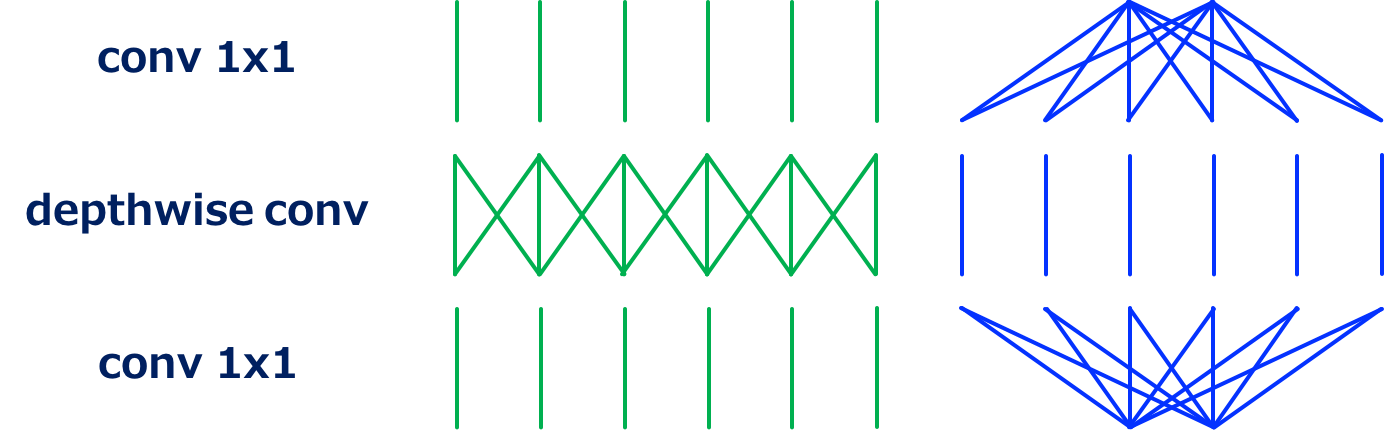
这样应该是能对通道信息进一步整合,避免了信息提取效率低下的问题。
V3
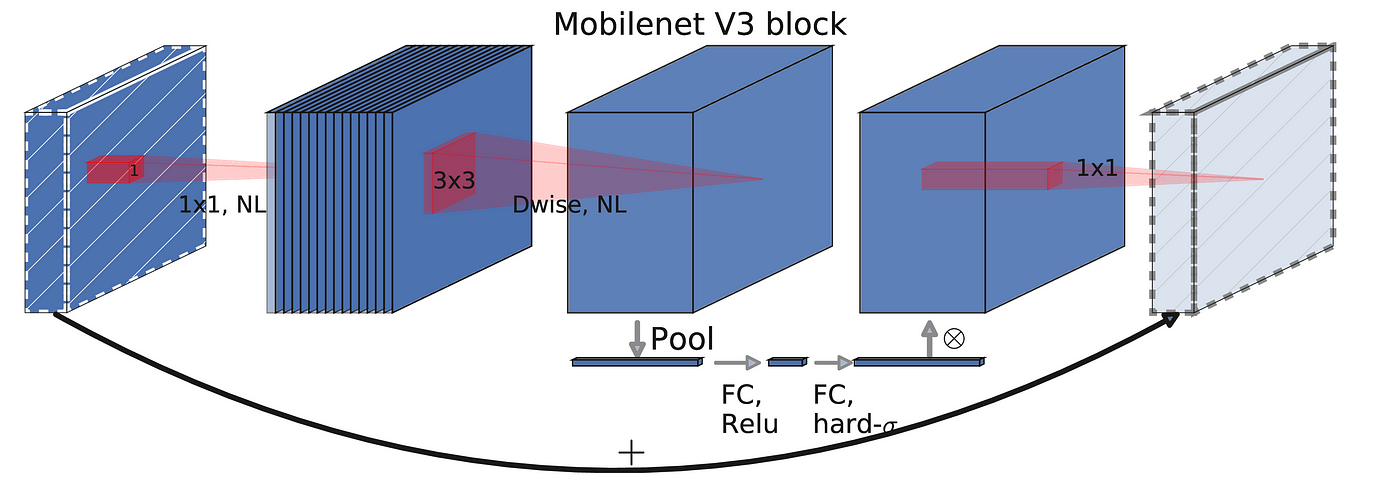
V3 是由 NAS(神经网络架构搜索)技术设计出来的网络模型,论文的重点就不是在介绍“MobileNet 如何好”了,而是“如何得到更好的 MobileNet”,感觉反倒是在介绍 NAS 技术。
这个模型相比较 V2 区别就没有很具有逻辑性了,优化了最后几层的结构,换用了 h-swish 激活函数和 ReLU6。
ShuffleNet
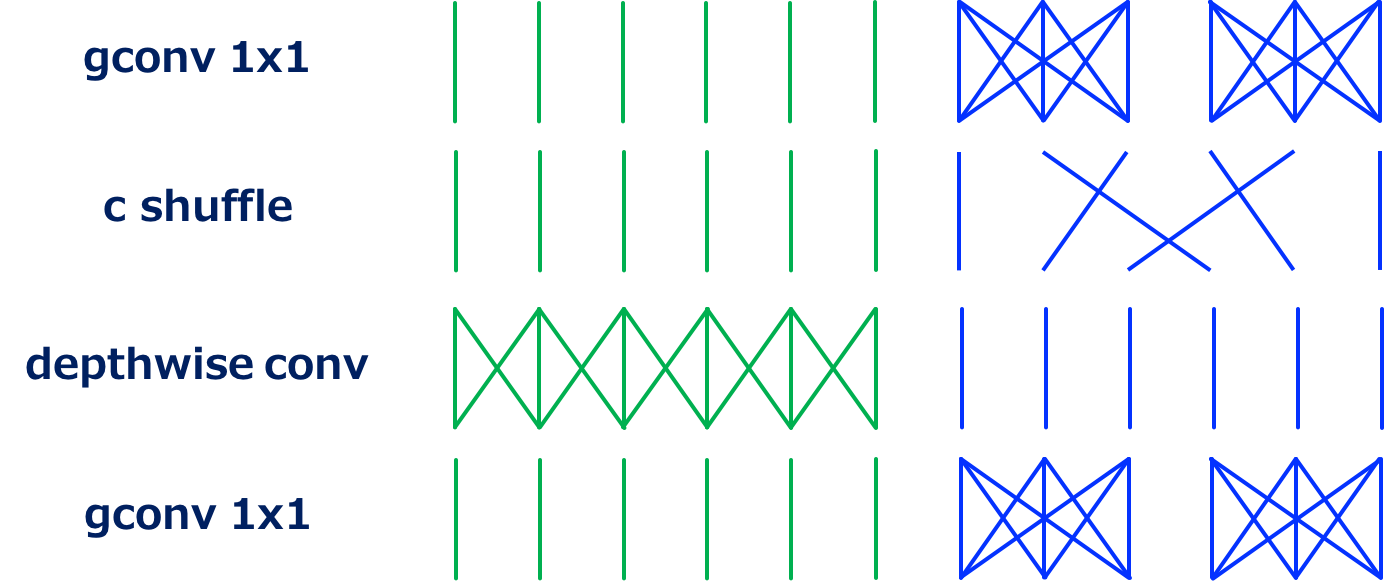
所谓 shuffle,就是打散、洗牌。为了弥补跨通道信息损失,ShuffleNet 提出了通过均匀打乱通道,使得信息在不同通道间流通的做法。
SENet & CBAM
SENet
所谓 SE 就是 Squeeze and Excitation,把特征“挤压”后再“激励”从而得到更好的效果,本质上是感受野的改变带来的效果。它是属于空间注意力机制,作为一种特征选择的方法,调节不同通道的强度。
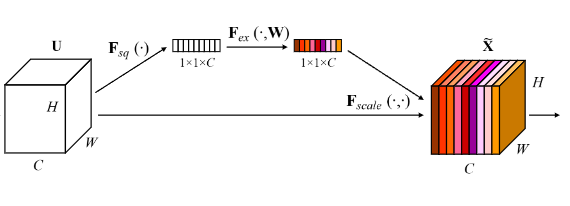
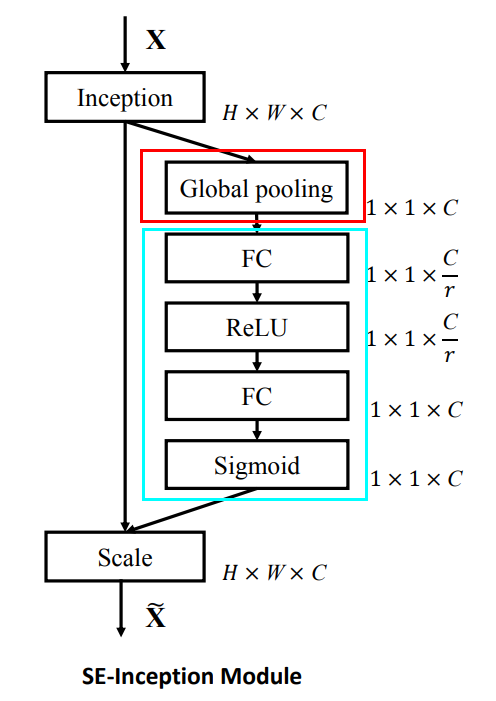
全局池化部分就是 Squeeze,获取全局感受野,FC 全局连接和非线性变换就是 Excitation 过程,构建特征通道的相关性。在 Colab 中补全训练函数并训练:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
net = SENet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')测试结果准确率可达 86.51%。
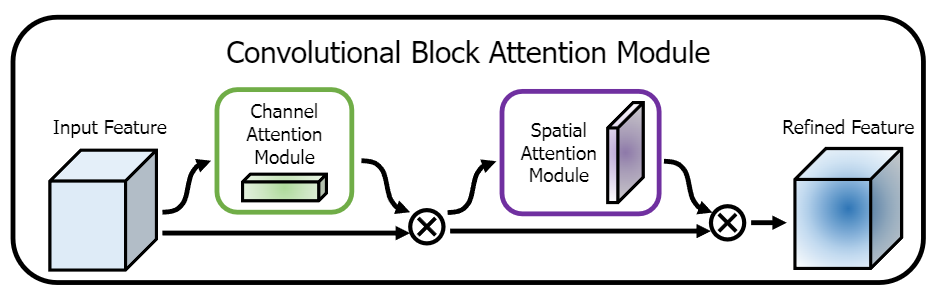
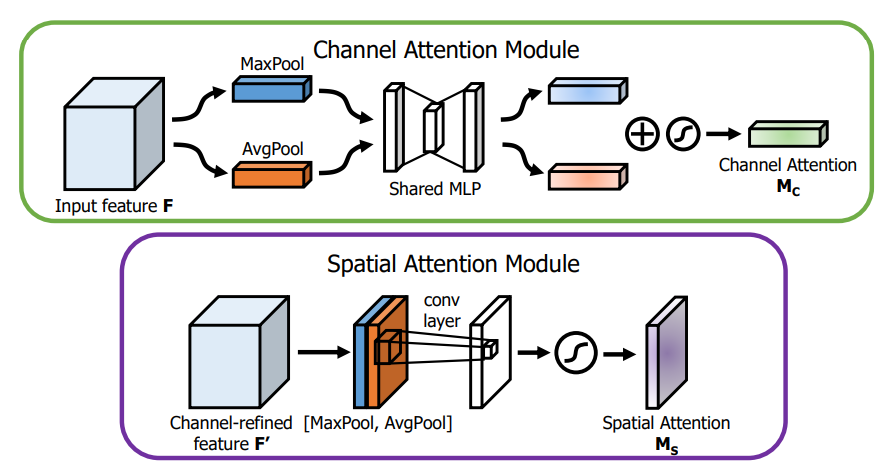
CBAM
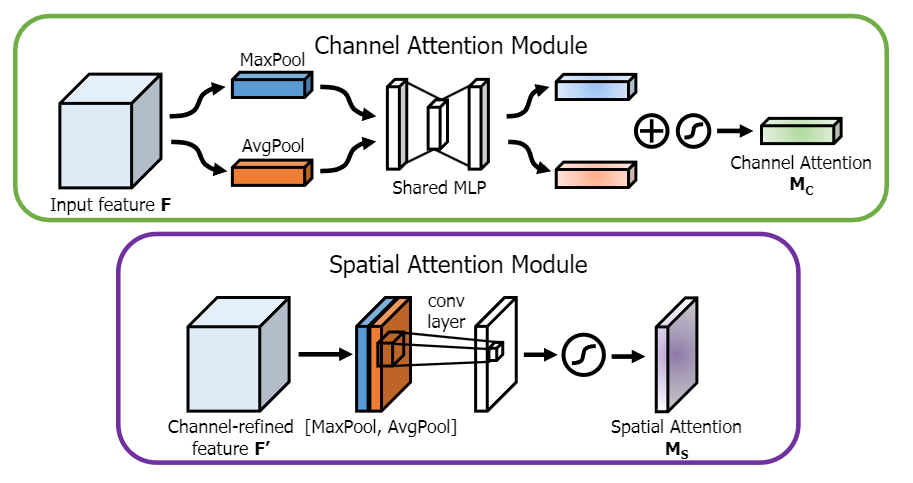
和 SE 相比,CBAM 更使用了空间信息做注意力权重的计算,达到跨通道的信息混合。同时使用 Max pooling 和 Average pooling,以期增加空间不变性,在通道注意力混合不同空间信息,而在空间注意力混合不同通道信息,再顺序性地组合两个区域。这个思想和前面的可分离其实很像,核心都在于分解反向以得到更高的效率。
HybridSN 高光谱分类
首先先按照要求补齐模型代码。这里还是简单用了个 ReLU 作为激活函数(好像就是 ReLU?)。
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv3d_1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=(1, 1, 1), padding=(0, 0, 0))
self.conv3d_2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=(1, 1, 1), padding=(0, 0, 0))
self.conv3d_3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(0, 0, 0))
self.conv2d_1 = nn.Conv2d(576, 64, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0))
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.4)
self.fc1 = nn.Linear(18496, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, class_num)
def forward(self, x):
x = self.relu(self.conv3d_1(x))
x = self.relu(self.conv3d_2(x))
x = self.relu(self.conv3d_3(x))
# 2D Conv
x = x.view(-1, 576, 19, 19)
x = self.conv2d_1(x)
x = self.relu(x)
# FC
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
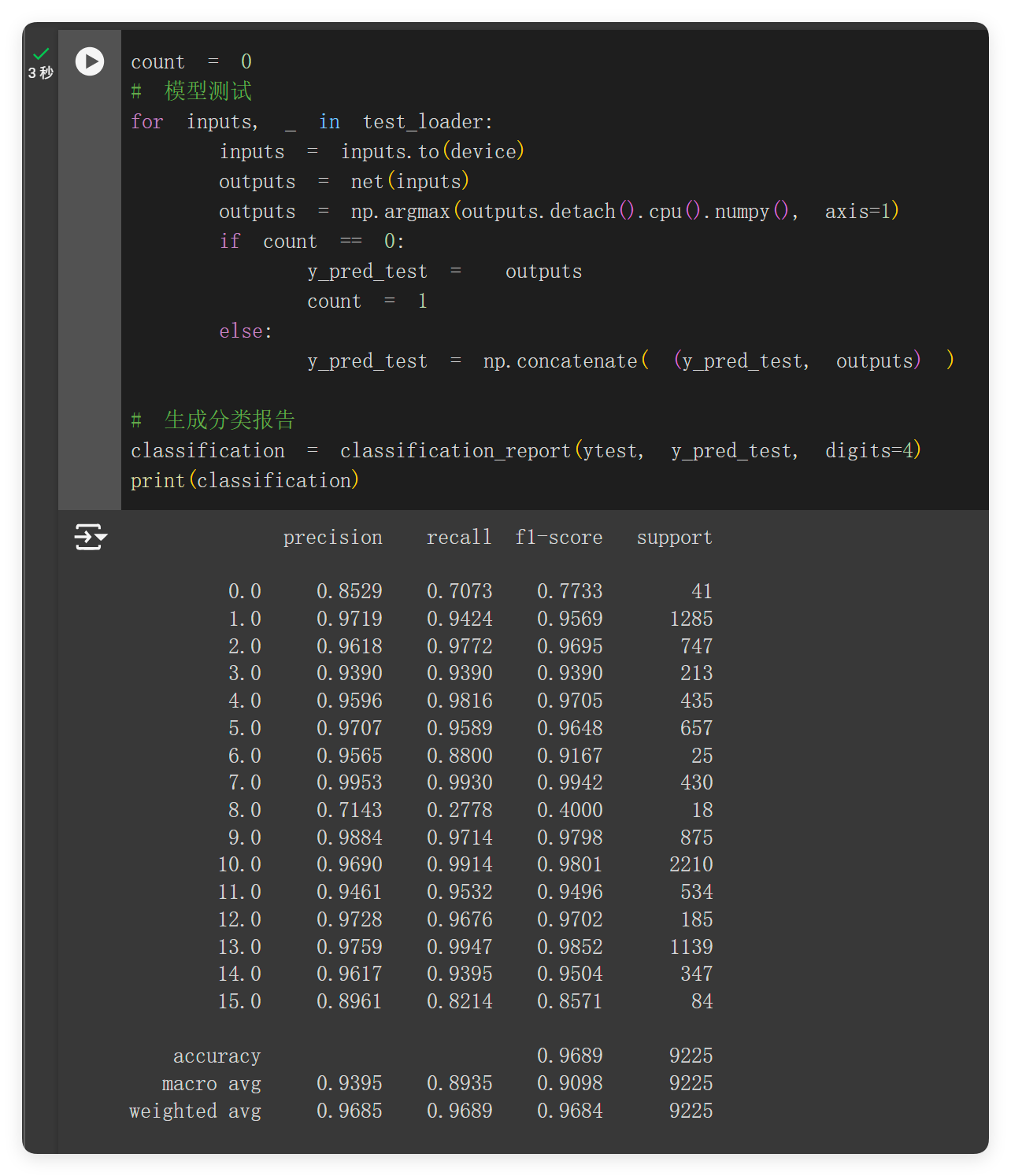
训练并测试,可以看到正常输出分类类别。准确率在 96.89%。

二、问题总结与体会
思考题
- 训练 HybridSN,然后多测试几次,会发现每次分类的结果都不⼀样,请思考为什么?



白天重新训练了一波,效果变差了一些。显然几次测试用的都是同一个模型,所以和训练过程等并没有联系,使用的是训练好的权重。我觉得原因是出在 0.4 的 dropout 上,随机关闭的神经元让预测结果变得随机。
如果想要进⼀步提升高光谱图像的分类性能,可以如何改进?
使用自注意力机制以更好地学习空间和光谱信息之间的关系,Attention is All You Need! 然后就是我觉得不同领域分类任务用的网络框架其实都大同小异,反倒是数据预处理 / 数据增强这一步可以进一步探究。
depth-wise conv 和 分组卷积有什么区别与联系?
深度卷积就是在深度这一个维度上作卷积,对每一个 depth-channel 作卷积;而分组卷积是将通道分组后再进行卷积。两者都用来减少参数量,但前者往往结合可分离卷积,结合 1x1 卷积整合通道信息,进而将计算量的乘法化为加法,而后者仅仅只是减少了一定倍率的计算量而且缺少通道信息的整合。极端情况下,分组卷积分成通道数量那么多组的时候,它和 depth-wise convolution 就没什么区别了。
SENet 的注意力是不是可以加在空间位置上?
可以,这样就可以得到类似于 CBAM 的网络结构。
在 ShuffleNet 中,通道的 shuffle 如何用代码实现?
查了代码可以看到:
pydef shuffle_channels(x, groups): """shuffle channels of a 4-D Tensor""" batch_size, channels, height, width = x.size() assert channels % groups == 0 channels_per_group = channels // groups # split into groups x = x.view(batch_size, groups, channels_per_group, height, width) # transpose 1, 2 axis x = x.transpose(1, 2).contiguous() # reshape into orignal x = x.view(batch_size, channels, height, width) return x它先将通道分组,每个组有
channels // groups个通道,然后将每个组的张量的第 1 和第 2 维度进行转置,最后再恢复到原来的 shape。所以实际上它并不是真的随机分组,而是一种有规律的打乱。
体会
神经网络处理视觉任务很大的一个问题就是参数量爆炸,如何在轻量化和好效果之间权衡前人作了不少研究。这次实验的深度可分离卷积就是其中之一,通过将卷积操作分解为深度卷积和逐点卷积,减少了参数量,同时保持了较好的效果。而 ShuffleNet 通过将通道分组,然后进行通道 shuffle,也是一种减少参数量的方法。感觉轻量化就是现在模型发展的一个大趋势,毕竟移动端上的计算资源有限,保证隐私和安全性也是一个重要的考虑因素。